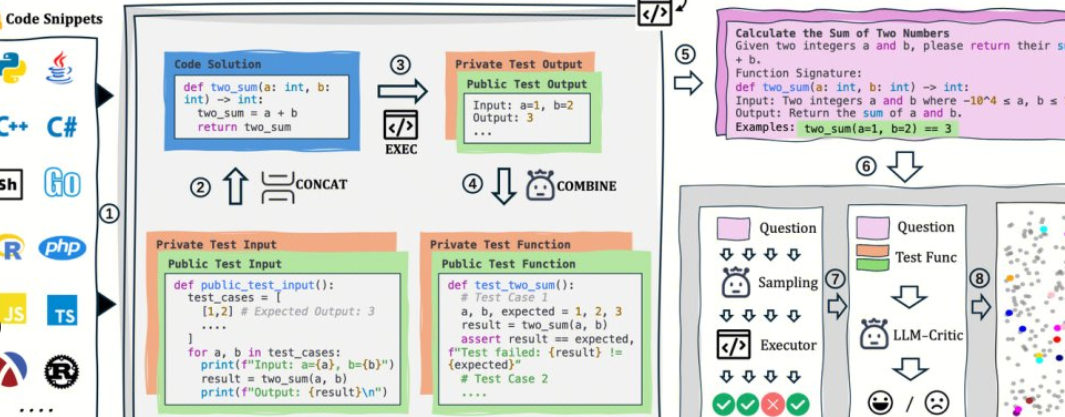
AutoCodeBench は Tencent の Hunyuan チームによってオープンソース化されており、その中核は「LLM 生成 + 多言語サンドボックス検証」の自動化されたワークフローです。 また、AutoCodeGen(データ合成)、AutoCodeBench(3セットのベンチマーク、Full/Lite/Complete)、MultiLanguageSandbox(30+言語サンドボックス)をオープンソース化して、BaseモデルとChatモデルの多言語コーディング能力を評価し、新しいベンチマークの自己生成をサポートします。
1. プロジェクトの概要と価値1
. 手動注釈なし: LLM を使用して質問と回答を参考にし、検証可能な標準出力がサンドボックスを通じて自動的に生成されます。
2. 多言語で難しい: 20 のプログラミング言語と 3,920 の実用的な問題をカバーしており、難易度の階層化は実際の開発に近づいています。
3. 評価とデータは同じソースです: 同じプロセスでデータを生成できるだけでなく、評価を再生できるため、再現性と水平比較に便利です。
2. オープンソースアドレス
1. プロジェクトホームページ: https://autocodebench.github.io
2. 論文: https://arxiv.org/abs/2508.09101
3. コードベース: https://github.com/Tencent-Hunyuan/AutoCodeBenchmark
4. データセット: https://huggingface.co/datasets/tencent/AutoCodeBenchmark
3. データとベンチマーク構成
1. フル: 3,920 の言語をカバーする 20 の質問で、難易度と多様性が強調されています。
2. Lite: 1,586 の質問、クロスモデルの「解決可能性」によってスクリーニングされ、迅速な比較により役立ちます。
3. コンプリート:1,000問、3ショット設定、ベースモデルのコード補完評価。
4. 言語と難易度:言語によるバランスサンプリングで、難易度は幅と強度の両方を考慮してイージー/ミディアム/ハードに分けられます。
4. 評価パラダイムと指標1
. 統一された命令: コマンドや例を実行せずに、単一のコード ブロックの出力が必要です。
2. サンドボックス検証: 生成されたコードをトピックごとにコンパイル/実行し、pass@1などの客観的な指標を計算します。
3. 2 行評価: チャットの生成とベースの完了を同時にカバーし、「対話モデルのみをテストする」というバイアスを軽減します。
5. すぐに始める (5 ステップ)
1. 出力を準備する: モデルを使用して、autocodebench.jsonl の質問のコードを質問ごとに生成し、model_output.jsonl として保存します。
2. イメージをプルします: docker pull hunyuansandbox/multi-language-sandbox:v1。
3. サービスを開始します: docker run -d --name sandbox -p 8080:8080 hunyuansandbox/multi-language-sandbox:v1。
4. ヘルスチェック: 最小サンプルを POST /submit に送信して、コンパイル/実行が正常であることを確認します。
5. 計算メトリック: ウェアハウス スクリプトを使用して、サンドボックスをバッチで呼び出し、実行結果を生成し、pass@1をカウントします。
6. 代表的なアプリケーションと適用可能なグループ1
. モデルチーム: 言語間の回帰とバージョン比較、コンパイルの失敗/境界のユースケースを特定します。
2. 科学研究評価: 高品質の多言語ベンチマークを低コストで構築し、再現性を向上させます。
3. エンタープライズ内部テスト: Lite/Complete を使用してグレースケール評価を行い、安定性とロングテールの質問を観察します。
7. 実用的な提案1
. 最初にライト、次にフル: 最初にすばやくスクリーニングし、次に包括的な回帰とレポートを実行します。
2. 同時実行とクォータ: サンドボックスのコンパイル/実行はボトルネックであるため、キューをスケジュールして分散的に実装することをお勧めします。
3. 可観測性: タイプ (コンパイル/実行/境界/時間制限)、ターゲットを絞った最適化プロンプト、ハイパーパラメータによるレコードの失敗。
4. RAGと協力する:長い質問やファイル間のタスクは、検索の機能強化と組み合わされて安定性を高めます。
8. 制限とリスク警告1
. 環境の一貫性: ミラーリングと依存関係は合格率に影響を与えるため、バージョンとランダム シードをロックする必要があります。
2. データコンプライアンス: トピックとコードに外部データベースが含まれる場合は、分離と監査を適切に行う必要があります。
3. 外挿境界: ベンチマーク スコアは本番環境の可用性と等しくなく、実際のビジネス サンプル A/B が依然として必要です。
9. よくある質問1
. 本当に「全自動で手動注釈ゼロ」なのでしょうか?
このプロセスは LLM の生成とサンドボックス検証を中心としており、トピックごとの手動アノテーションには依存しません。 品質を確認するために、主要なサンプルの手動サンプリングをお勧めします。
2. どの言語がサポートされており、Python に偏っていますか?
サンドボックスは 30+ 言語をサポートし、データ バランシングを備えた 20 のプログラミング言語をカバーし、「Python のみ」のバイアスを大幅に減らします。
3. Chat と Base を同時に評価するにはどうすればよいですか?
チャットは、統合されたシステムプロンプトから直接コードを生成します。 Baseは、Completeの3ショットコンプリート設定を使用して、評価プロトコルの一貫性を保ちます。
4. 同じワークフローを使用してカスタム ベースラインを生成できますか?
わかりました。 AutoCodeGen は、同じ検証および採点プロセスを使用して、サンドボックス内の新しい問題とテスト セットを自動的に合成します。



